Compapp Linux Cluster - 136.206.19.228
(School of Computer Applications, Dublin City University, Ireland)
1. About the Cluster
The cluster consists of 23 old Dell machines from the CA labs,
each a PPro 266 MX with 32 Megs of RAM running Debian Linux. It is
a 'Beowulf' style cluster meaning one of the machines (tehran) is
the "head node", and the rest are compute nodes (no monitor/keyboard)
which simply compute jobs given to them and send back results.
Development environments MPI and PVM are both available, as well as
C or FORTRAN.
The cluster was put together voluntarily by a small group from
RedBrick, the DCU Networking
Society, during the month of August 2001 as a proof of concept. It
is open to anyone within the school who wishes to use it to learn
about Parallel & Distributed systems or clusters in general. It is
NOT by any means intended to be a high-availability, reliable
computing resource, so please don't treat it as such :-)
2. Getting Started
To get an account on the cluster, send an email request to Karl Podesta,
(CA4 student, me!), at kpodesta@redbrick.dcu.ie.
To access the cluster you will have to use a method called SSH
(or Secure SHell). This is like a secure version of telnet - all the
traffic between you and the cluster is encrypted. If you are on an
MS Windows platform, the excellent
PuTTy
program is recommended. Download it via the link, put in the IP address
136.206.19.228 under "Host Name", make sure the protocol is
'ssh', then simply click open. You will be prompted for a username
and password. If you are on Solaris/Unix, simply type
ssh -l username 136.206.19.228 (replace with your username).
You will then be on 'tehran', the head node of the cluster. This is
the only machine that you should ever access - any parallel programs
that you run should be run from here: it is the interface to the cluster.
3. Using the Cluster
NOTE TO CA405 CLASS - Don't bother with the queuing
system outlined below - to run your mpi programs, simply do "mpirun
path/to/your/program" - eg, mpirun ~/cpi (to run cpi from your home
directory, '~')
Although it is possible to run parallel jobs directly from the command
line, this can cause things to descend into havoc if there are many
people on the cluster running programs at the same time. It is for that
reason that we use a Queueing system on the cluster, the particular
system that we use is called PBS (or Portable Batch System). Jobs
are submitted to this rather than being run from the command line directly.
To submit a job, you need to encapsulate it in a small shell script
which contains the commands that you want to run, and which also contains
any options that you want to tell the batch system (such as how long
the job is to be run for, how many processors it uses, what queue if
any you want it to go into, etc.). You then submit this script to the
queueing system via the command: qsub myscriptname
When you press enter, you will get a number thrown back at you. This
is the id number of the job in the queue. When the job finishes, whatever
output is generated will be dumped into a file in your home directory
prefixed with the name of the job, and indexed by this number.
(eg "testjob.o34")
Here is an example of one of these job scripts:
#PBS -S /bin/bash
#PBS -N joetest
#PBS -q small
#PBS -j oe
echo Time is `date`
echo Directory is `pwd`
# Pause for 2 minutes
sleep 120
# Now run the MPI prog using the nodes
mpirun -machinefile ~/machines -np 8 ~cluster/MPI/examples/basic/cpi
The "#PBS" headers at the top define some options to the queueing
system, the first defines the shell to use to execute the script,
the second (-N) defines what the job is to be called in the queue,
the third (-q) specifies what queue it is to run in, and the last
just combines the output and errors into one file. The script pauses
for 2 minutes before executing just so you can see the job in
the queue before it finishes (as it only takes a few seconds to complete).
When the job has been submitted, type qstat -a to get a list of
all the jobs in the queue on the cluster. You should be able to see
the name of your job in there. You can also type qstat -Q or
qstat -q to give you info about the number of jobs executing
in the queue on the cluster in total.
The "machinefile" option to mpirun instructs your MPI program
to use machines (nodes) in the cluster only which are listed in
that file. In this case, the file "machines" has a list of 8 of
the nodes from the cluster.
4. A quick tutorial
Let's start from scratch with an example, calulating Pi is a nice easy one.
The source I'm using is one of the standard MPI examples,
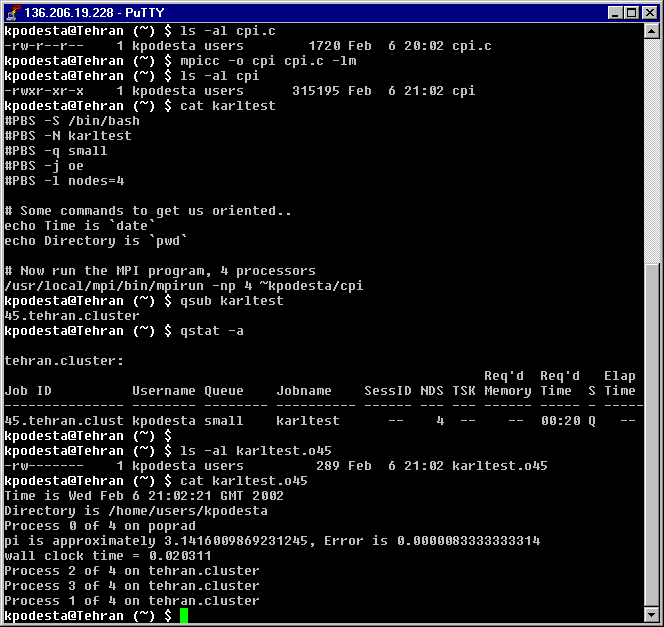
it simply calculates Pi without any user input. Following below is a screenshot
of my terminal and the commands I used. Firstly I compiled the source code
for MPI (C compiler). Then I showed the contents of a file called "karltest"
which is the script file I use to submit the mpi job to the queue.
"qsub karltest" was the actual command used, and a number was
returned to id my job in the queue. "qstat -a" was used to show
all jobs in the queue (only mine was there, and only for a few seconds).
The results from the job were dumped to a file in my home directory starting
with the name of my job, and finishing with the id number ("karltest.o45").
Here is the file karltest.
If there is nobody else on the cluster (run users), and your job
is very small, you can avoid this hassle by simply running your MPI job
from the command line ala mpirun -np 4 ~/cpi. However DON'T
do this if there are other users on the cluster, or if your job requires
more computation than a simple Pi program - use the queue, it's there to
help everyone gets fair access to the cluster, and you wouldn't want your
job to be affected by some fool hogging all the resources (theoretically
speaking :-) ). Please treat the cluster with a bit of respect, it's
by no means bulletproof, but it's useful enough. Otherwise, WE KNOW WHERE
YOU LIVE. etc.
5. More Information
There are plenty of examples on the web of PBS scripts, options
to PBS, and lots of information and docs on programming in MPI
as well - a typical Google
search will more often than not yield what you're looking for.
It is important to remember that PBS scripts are only really a
'shell' (in the egg sense, not the unix sense!) for running your
jobs through. More than likely your efforts will have been concentrated
on bulding an MPI program or the like - submitting them through a
PBS script makes sure that the job is queued (so thus your job gets
entire control of the cluster! For a certain period of time of course),
and that it doesn't clash with someone else's job.
If you're interested in how the cluster was built, historically speaking,
you can check out the cluster-group mailing list
archives for the
summer of 2001.
Karl Podesta, kpodesta@redbrick.dcu.ie, 6th Feb 2002