VRRP for redundant network services
DRAFT DRAFT DRAFT
Abstract
The Virtual Router Redundancy Protocol (VRRP) was developed to eliminate single points of failure in statically routed, default gateway environments. In this paper I make use of VRRP to provide redundant access to network services rather than routing paths. I use a VRRP ``virtual router'' as a method of providing cheap, reliable and standards based redundancy for a group of hosts serving common internet network services. I provide configuration hints and highlight problems that may be encountered.
Contents
- Abstract
- Virtual Router Redundancy Protocol (VRRP)
- Test environment
- Miscellaneous notes
- Test results
- Advanced techniques
- Pitfalls
- Security considerations
- Conclusion
- Notes
Virtual Router Redundancy Protocol (VRRP)
VRRP is described in RFC 2338 as:
VRRP specifies an election protocol that dynamically assigns responsibility for a virtual router to one of the VRRP routers on a LAN. The VRRP router controlling the IP address(es) associated with a virtual router is called the Master, and forwards packets sent to these IP addresses. The election process provides dynamic fail over in the forwarding responsibility should the Master become unavailable.
VRRP was conceived to solve the problem of end-host over reliance on a statically configured default routing gateway. Should the gateway cease to function, the hosts it services become completely stranded. VRRP, similar to the proprietary Hot Standby Router and IP Standby protocols, allows an administrator make an IP address into a virtual address, dynamically assigning it to any member of a VRRP group. Each group is denoted by a number, called a VRID. In this fashion, the responsibility for the virtual address can be moved from one host to another either by administrative intervention or automatic detection of a failure. A master makes a multicast announcement of its health periodically. An announcement of this type is called heartbeat. Hosts which are not the master for a given VRID are referred to here as backups or slaves. Should the master's heartbeat not be received for a period of time the slaves for a VRID will promote one of their kind to be the new master.
These characteristics are desirable for more than routers. VRRP is generic enough -- in essence it moves an IP address among hosts -- to be taken advantage of in end-host service provision.
In this paper I create a VRRP virtual group composed of servers which will provide redundant access to a set of common internet services. These hosts are not routing devices. The addresses publicised to clients for service provision are virtual addresses managed by VRRP.
Test environment
Operating system, hardware, network
I use three systems. The ``servers'' are a pair of Pentium class PCs running FreeBSD 4.7-RELEASE-p3. The network ``client'' is a Windows 2000 laptop. The three share a single ethernet on an eight port hub.
The preferred server, clarinet, is 10.10.10.6 and has a priority which will make it the master whenever it is available. The backup server is fridge and uses 10.10.10.2. It has a low priority which means it will become master only when clarinet becomes unavailable. Together they share one virtual group and a number of virtual service addresses. The client, jimbob, is 10.10.10.5.
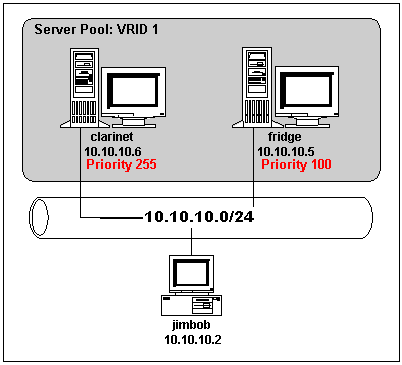
The simple test network is illustrated above.
Simulation of failure and recovery
I simulate a system failure affecting clarinet by disconnecting its network cable. Given that, recovery is obvious. Reconnect the cable.
VRRP software
freevrrpd
I use the freevrrpd daemon from http://www.bsdshell.net/.
FreeBSD users can install it very simply, using the port skeleton in
/usr/ports/net/freevrrpd. VERSION!!
freevrrpd is in early development but performed well in
the tests. A very useful feature is the ability to execute a command
when a host becomes a master and a command when it becomes a slave. This
simplifies the task of notifying applications that the available
interfaces on a host have changed. I use a shell script in each case so
I can perform a number of tasks when there is a failover, and the tasks
can be changed without needing to restart freevrrpd. I'll
refer to these scripts as event scripts.
Configuration
I use an intentionally simple configuration file, needing only one VRID. I use password authentication to raise the bar for blind spoofing. See the Security considerations section below. The configuration file from fridge is shown below:
[VRID]
serverid = 1
priority = 100
addr = 10.10.10.53/32,10.10.10.80/32,10.10.10.25/32,10.10.10.22/32
masterscript = /usr/local/etc/vrrp/vrid1_master.sh
backupscript = /usr/local/etc/vrrp/vrid1_backup.sh
password = foobingbaz
interface = xl0
The configuration on clarinet differs only in its priority; clarinet uses 250. The higher priority selects itself as the master.
On the surface, the addr line may seem strange. I have
always preferred, when possible, to use separate IP addresses for
distinct services. It gives me more options to relocate services in the
event of problems. freevrrpd supports more than one virtual
IP address per VRID so I can combine VRRP with the flexibility of
separate addresses. An individual service can be moved to another
machine (or VRID) very easily.
I place the events scripts in their own directory. I recommended you give them names that clearly show the VRIDs that use them and whether they are a masterscript or backupscript.
Leg work
Startup scripts
For each application you should have a method of starting it if and only if it is not already running. The first invocation of the start method should do as requested. Subsequent requests should notice the application is already running and just exit successfully. This will greatly simplify your masterscript.
INADDR_ANY
Generally speaking you're going to encounter problems with programs
that want to bind a socket on each interface that is present on the
machine. A problem arises on the slave hosts. An application started on
a slave cannot bind a socket to a virtual address because the virtual
interfaces are not present on the system until it becomes a master. How
can you bind on an interface that doesn't yet exist? You can't. Where
possible you want your applications to bind to the wildcard, INADDR_ANY
(a.k.a 0.0.0.0, ``*'' in the output of netstat). The kernel
will take care of getting packets to the application when it becomes a
master.
Who's there?
An administrative requirement that is common to each case examined below is the need to be able to determine which host is home to a virtual address at any given moment. You may just be inquisitive or you may like your system monitoring to flag when a virtual address has moved onto a backup server, or vice versa.
For each of the services tested I've included a straightforward suggestion on how this could be achieved. It's not rocket science so I don't labour on the point.
Data consistency
An obvious meta-requirement is keeping members of a virtual group in sync. You need to be sure, for example, that your web servers all have the same copy of your website. The mechanics of that are outside the scope of this paper.
Application installation
I'm assuming that the software used here is installed in a somewhat
conventional manner, in line with its documented procedure. I'll expect
supporting programs such as apachectl, svc or
tcpserver are installed and usable. I won't be using
explicit paths for binaries. That's up to you and your administrative
conventions.
Test results
World wide web
Apache
The Apache HTTP server works in the VRRP configuration, in both 1.3.x
and 2.0.x guises, without any hoop jumping. Apache's default socket
binding behaviour works perfectly. It will bind to INADDR_ANY by
default. You should read up on Apache's Listen and
BindAddress directives if you need to change that
behaviour.
HTTPS/SSL servers need a little extra care. Your SSL certificates will be validated by clients based on the host name they use to access the site. You should make sure that the same certificate is on both servers and remember to update both when the expiry date comes around.
To determine the name of the master, put a file named whoami
in the DocumentRoot of each host. Point a web browser at
the virtual server and request /whoami.
publicfile
Electronic mail
sendmail
The default for sendmail is to bind a socket to the wildcard
interface, which suits our needs perfectly. If for some reason your
sendmail does not do this, you can use the DAEMON_OPTIONS
statement to force it to. Remember that if you use an MSA you will need
to specify this statement twice to apply it to the MTA and MSA
listeners.
DAEMON_OPTIONS(`Addr=0.0.0.0')dnl
sendmail will use its idea of the system name in its default greeting:
220 fridge.example.org ESMTP Sendmail 8.12.6/8.12.6; Wed, 5 Mar 2003 19:41:45 GMT
If you dislike how much information it discloses, as I do, you can modify its notion of the system name -- though this affects many things -- or completely replace the 220 response text.
#
# Change the system name ($j macro). This will affect headers,
# masquerading, unqualified sender delivery and a raft of other things.
#
define(`confDOMAIN_NAME', `fridge.example.org')
#
# I prefer to leave that alone, and instead replace the 220 response
#
define(`confSMTP_LOGIN_MSG', `$j ESMTP No UCE')
Note that the first word of a 220 response must be a FQDN, and a sendmail server will parse the second word to determine whether the host talks SMTP or ESMTP.
qmail
tcpserver -vHPR 0 smtp /var/qmail/bin/qmail-smtpd
tcpserver -vHPR 0 pop3 /var/qmail/bin/qmail-pop3d
control/me, control/smtpgreeting
Name resolution
Common observations
Restarting your cache will lose its contents. The nameserver will operate at reduced performance until it again populates its cache with a reasonable working set of data.
A caching resolver needs to send queries to other nameservers in the process of answering a client query. Some people get worked up about whether these queries should have a source address showing the virtual address or the host's real address. Personally I don't think it matters all that much. It probably should be from the real address but if it's not and a failover causes the new master to receive a reply to a query it didn't send the world keeps turning.
env/IPSEND, query-source
ISC BIND
Versions 8 and 9 do not differ significantly in the areas that matter for this paper.
BIND will bind a separate socket to each interface on the system.
This presents a significant problem, the solution to which is your
choice of the lesser of two distinct evils. When a host becomes a master
named needs to be told to check for new interfaces, so it
can attach a socket to the virtual interface address. You have two
alternatives to accomplish this, neither of which is pleasant.
- Do not run
namedas an unprivileged user, use reload namedneeds to attach a socket to port 53, which can only be done by UID 0. If you runnamedas an unpriv. user, once it has dropped privs it cannot attach to port 53 when the master address moves here. If you run it as root, causing a reload will rescan the interfaces -- BIND 8 will stop answering during this time though -- and pick up any changes. Alternatively, you could use theinterface-intervalstatement to scan automatically. Minimum of one minute though.- Full restart of
named. - When it starts up it will bind to each interface, including the now present virtual address. This can take time, especially if you are serving a few hundred zones. While BIND8 is loading it will not answer any queries which means downtime. BIND9 will answer for the zones it's loaded so far. Also, if BIND is a caching resolver you will have lost the contents of your cache -- the nameserver will operate at reduced performance until it populates its cache with a reasonable working set of data. Means can run as non-root.
Your masterscript should do the necessary.
If your named configuration file already uses a listen-on
{}; statement, you should make sure to include the virtual
addresses. XXX what errors does named say when specified addrs aren't
here.
Server identification is done with a TXT resource record. Add a zone called who.ami to the named configuration file.
zone "who.ami" IN {
type master;
notify no;
file "zones/who.ami";
};
and include in the zone file a TXT record giving the host's name:
$TTL 12H
@ IN SOA vrrp-ns.example.org. dns.example.org. (
2003030100 ; serial
3600 ; refresh
1800 ; retry
2592000 ; expire
3600 ) ; nxdomain ttl
IN NS vrrp-ns.example.org.
IN TXT "fridge"
Then query for the TXT RR of who.ami using your favourite DNS query tool. The output from DiG is below.
djbdns
djbdns separates the functions of caching resolver (dnscache), udp authoritative server (tinydns) and tcp authoritative server (the confusingly named axfrdns) into different programs. I will look at them in two sections.
dnscache
Trickier - use root/servers to force zone to auth. server with appropriate data, or tinydns on localhost (clash with INADDR_ANY?). Client differentiation, with root/servers/who.ami
tinydns / axfrdns
The tinydns data storage mechanism means it does not have to read in zone data when it starts up. It starts, and is ready to answer queries, immediately. Therefore automatically stopping and starting it is quite practical. To start tinydns when transitioning to a master, use:
svc -u /service/tinydns
in the masterscript and
svc -d /service/tinydns
in the backupscript to stop tinydns when becoming a
slave.
I used the same identification method with tinydns as with BIND. Add a TXT resource record called who.ami to /service/tinydns/root/data:
.who.ami:10.10.10.53:vrrp-ns.example.org 'who.ami:fridge:300
Use your favourite DNS query tool to query the virtual IP address to see which system is the master:
bash-2.05a$ dig @10.10.10.53 who.ami txt +norec ; <<>> DiG 8.3 <<>> @10.10.10.53 who.ami txt +norec ; (1 server found) ;; res options: init defnam dnsrch ;; got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 6024 ;; flags: qr aa; QUERY: 1, ANSWER: 1, AUTHORITY: 1, ADDITIONAL: 1 ;; QUERY SECTION: ;; who.ami, type = TXT, class = IN ;; ANSWER SECTION: who.ami. 5M IN TXT "fridge" ;; AUTHORITY SECTION: who.ami. 3D IN NS vrrp-ns.example.org. ;; ADDITIONAL SECTION: vrrp-ns.example.org. 3D IN A 10.10.10.53 ;; Total query time: 2 msec ;; FROM: fridge.botanic.ave to SERVER: 10.10.10.53 10.10.10.53 ;; WHEN: Sun Mar 2 15:07:09 2003 ;; MSG SIZE sent: 25 rcvd: 93
Remote access
It's not immediately obvious why anyone would want SSH shared between a number of different machines. Surely, you say, remote access is required to particular hosts, not a virtual host which might be any one of the VRRP group. That said, perhaps you want to SSH to 'the active web server' or similar. It's not my place to judge ... :)
OpenSSH
ListenAddress 0.0.0.0 (the default) will work. Your
SSH client will (should) warn you about modified host keys if you
connect after a failover has occured. While this is expected, you should
make sure this doesn't condition you out of paying attention to these
warnings. Without them, SSH is useless.
The Banner option can make sshd print the
contents of a file before prompting the user to login. Mentioning the
system's hostname easily identifies which host you are connecting to.
Your sshd_config might contain:
ListenAddress 0.0.0.0
Banner /etc/issue.net
And /etc/issue.net might say:
fridge.example.org - No unauthorised access
Advanced techniques
Load balancing
A crude but effective (and cheap) method of load-balancing is to use multiple DNS A records, announced with a low time-to-live (TTL) owned by a generically named label, such as the following resource record set (RRset):
mail.example.org. 600 IN A 10.20.1.1
600 IN A 10.20.1.2
600 IN A 10.20.1.3
600 IN A 10.20.1.3
This relies on the common behaviour of DNS servers to either randomise or round-robin the order of the A records. Over time, in the above example, 10.20.1.3 would receive half of the incoming connections while the other hosts would receive a quarter each.
A serious flaw of such setups is that unresponsive hosts cannot quickly be removed from the service pool. Any change (manual or automatic) to the RRset won't be fully effective until the time specified by the TTL period has elapsed. In the above example, if 10.20.1.3 were to fail, approximately half of new sessions would have to wait for the client to timeout and try another A record. Particularly unlucky clients may end up getting the second 10.20.1.3 record and failing again. For this reason DNS round-robin based load-balancing is considered a poor choice, forcing administrators to choose more exotic, and expensive, solutions.
VRRP makes DNS load-balancing a feasible option. The cost of DNS load-balancing is the danger that one of the IP addresses published in the DNS may become unavailable, thereby causing service disruption until it can be removed from the RRset. Using VRRP virtual addresses in A records reduces that danger considerably. By using two VRIDs between two hosts -- each a master for one -- you can use DNS to split the load across both but with confidence that should either fail the other will step in and provide service for the other VRID.
[VRID]
serverid = 50
# master for VRID 50: 10.10.1.50
priority = 250
addr = 10.10.1.50/32
masterscript = /usr/local/etc/vrrp/vrid50_master.sh
backupscript = /usr/local/etc/vrrp/vrid50_backup.sh
password = crashbangbump
interface = xl0
[VRID]
serverid = 55
# slave for VRID 55: 10.10.1.55
priority = 100
addr = 10.10.1.55/32
masterscript = /usr/local/etc/vrrp/vrid55_master.sh
backupscript = /usr/local/etc/vrrp/vrid55_backup.sh
password = whizzflump
interface = xl1
With a little DNS, you can distribute load as one-third, two-thirds without fear of disruption should either server fail using:
mail.example.org. 600 IN A 10.10.1.50
600 IN A 10.10.1.55
600 IN A 10.10.1.55
Adding and removing VRRP servers
Introducing a new machine intended to be a master is seamless. Set its priority appropriately and let the VRRP election do the work.
Stopping a master is a little more involved. The next preference slave will not promote itself until three times the heartbeat interval have passed if you simply disconnect the master. It's certainly not the end of the world but if you have advance warning there's no excuse for not having a smooth transfer of service.
Instead, modify the configuration of the slave you wish to become
master and set its priority to higher than the current master. Then HUP
freevrrpd on the slave. The reconfigured slave will become
a master without any service interruption. Once that is completed the
original master -- now an inactive slave -- can be brought down without
impact.
Preventing failback after a failover
In some circumstances you may not want a master which experiences a problem, fails and subsequently recovers to resume responsibilty as the VRID master. Perhaps you insist on an a formal investigation of the cause before it resumes service, or you want to prevent flapping -- repetitive failures and recoveries in quick succession which would cause significant disruption to remote clients as the VRID moves to and fro.
Modify the freevrrpd.conf in a masterscript
Pitfalls
Be very, very wary of using the highest priority, 255. A host with a priority of 255 cannot be demoted to a slave. Such inflexibility works against the whole point of deploying a VRRP group. Refer to the Adding and removing VRRP servers section for why this is such a bad idea.
Any output from the event scripts is discarded - you will need to be
sure they are quite clever as they're not going to be able to tell you
what's gone wrong unless they write their own logs or submit messages to
syslog.
Use one VRID per physical interface. VRRP moves not only IP addresses
but a computed ethernet MAC address among hosts. The computation is a
function of the interface's VRID. freevrrpd will recompute
the VRRP MAC as it reads additional VRIDs from its configuration, which
will cause it to apply in rapid succession a number of different MAC
addresses to an interface. Should a client send an ARP query for the MAC
of a VRRP IP address while freevrrpd is setting up multiple
VRIDs, the client may receive a reply including an intermediate MAC
instead of the final MAC. That client will be unable to communicate with
the virtual address until its ARP cache entry times out.
Security considerations
Common sense dictates that you restrict physical access to the network segment you use for your server LAN. Someone who can place VRRP announcements onto your server segment could announce their system with a high enough priority to acquire master status for your VRIDs. You can use password authentication to raise the bar for blind spoofing. That said, anybody starting a rogue VRRP daemon on your ethernet can likely sniff traffic and will quickly pick up your password. Use a separate, dedicated ethernet segment for your important systems.
It should go without saying, but I'll say it anyway: none of
this, in any way, removes the responsibility to keep your system and
applications patched and current with respect to security
vulnerabilities. This also applies to freevrrpd itself.
The freevrrpd daemon needs a bpf device.
Without it, it cannot run. Personally I'm not concerned by the presence
of bpf devices but some security recipes recommend removing
them. If you have followed such instructions you will need to add a
pseudo-device statement to your kernel configuration and
rebuild. The GENERIC kernel already includes the
following:
# The `bpf' pseudo-device enables the Berkeley Packet Filter.
# Be aware of the administrative consequences of enabling this!
pseudo-device bpf #Berkeley packet filter
which will work fine.
Conclusion
Yeah, a conclusion. Why not. Writing one sounds like a good idea.
Notes
- RFC 2338: Virtual Router Redundancy Protocol
- IETF VRRP Working Group